Public discussion around criminal AI use still tends to center on branded underground tools like "Evil-GPT" and "FraudGPT." Those were important early signals, and we covered them in earlier reporting. But the forum activity behind this report points in a different direction. Rather than pouring time and money into dedicated criminal models, actors are increasingly focused on manipulating mainstream models, jailbreaking commercial ones, or shifting to uncensored open-weight models with fewer guardrails.
What's emerging instead is a broad underground market around AI access and enablement. That market spans jailbreak prompts for frontier models like Claude, Grok, and ChatGPT; discounted premium AI accounts and plan resales; subscriptions for weaponized "dark" LLMs; community-curated lists of uncensored models and related tools; and specialist services to build deepfake software, AI call centers, retrieval-augmented generation (RAG) systems, AI-powered Telegram bots, and other workflow components.
We're also starting to see signs that AI may be used to build the underground ecosystem itself, not just the tools traded within it. Reports of AI-generated dark-web forums suggest threat actors could soon create convincing new forums, marketplaces, or scam communities faster and more cheaply. It's still early, but it's realistic to expect more AI-built or AI-assisted underground forums as the cost of standing up convincing criminal infrastructure continues to fall.
The Economics Favor Abuse, Not Building
Building an effective offensive AI tool is expensive, technically difficult, and still unreliable. Cybercriminals hit the same constraints as everyone else: API and token costs, tool integration, hallucinations, context limits, and the difficulty of turning a model into something stable. That helps explain why so much of the underground market is focused on access rather than innovation.
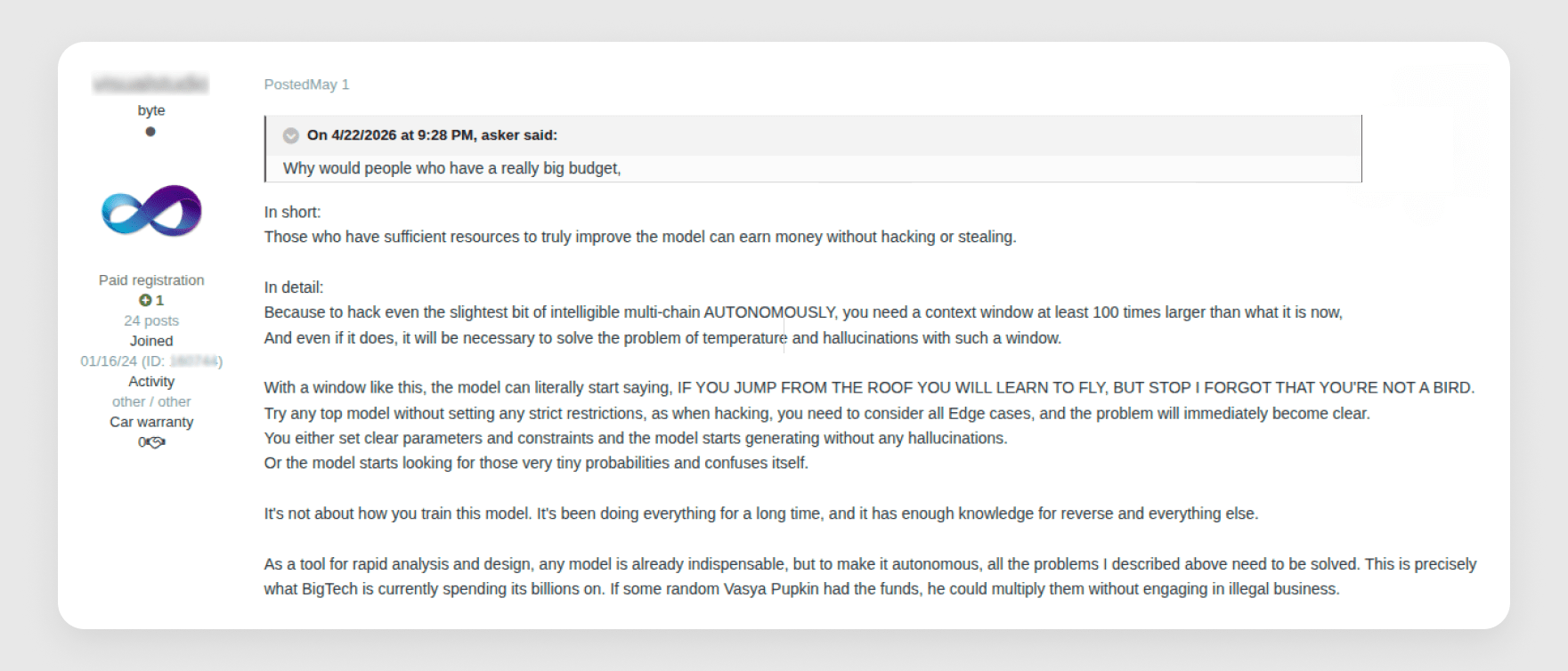
In one forum discussion asking why no-one had built a genuinely capable "AI hacker" yet, the responses were revealing (see Figure 11). The core argument was that a model capable of autonomously handling real hacking tasks would need a context window far larger than current models offer, would still struggle with hallucinations, and would require resources and funding far beyond what most criminal operators can afford.
That aligns with the broader pattern in both the forum data and the incidents in this report. For most actors, abusing an existing model is far more realistic than building one.
The Model Trade-Off Actors Are Navigating
Threat actors typically choose between a small set of model types based on capability, reliability, cost, and operational control. In practice, the discussion revolves around frontier models, uncensored open-weight models, smaller lightweight models, and, less often now, weaponized "dark" LLMs.
The preference pattern is fairly clear. Frontier models still appeal when actors want higher-quality output or deep research, which is why jailbreak prompts to bypass safety guardrails for models like Claude, Grok, and ChatGPT continue to circulate, even as these models become less reliable for malicious use because of tighter guardrails and moderation. But the more durable preference appears to be shifting toward uncensored open-weight models (see Figure 12). They're more predictable, can run locally for privacy, and don't depend on a cloud provider keeping a session alive. Models like Qwen, Dolphin, and Mistral lack the performance ceiling of frontier systems, but many actors appear willing to make that trade. For their purposes, reliability and control often matter more than peak capability.
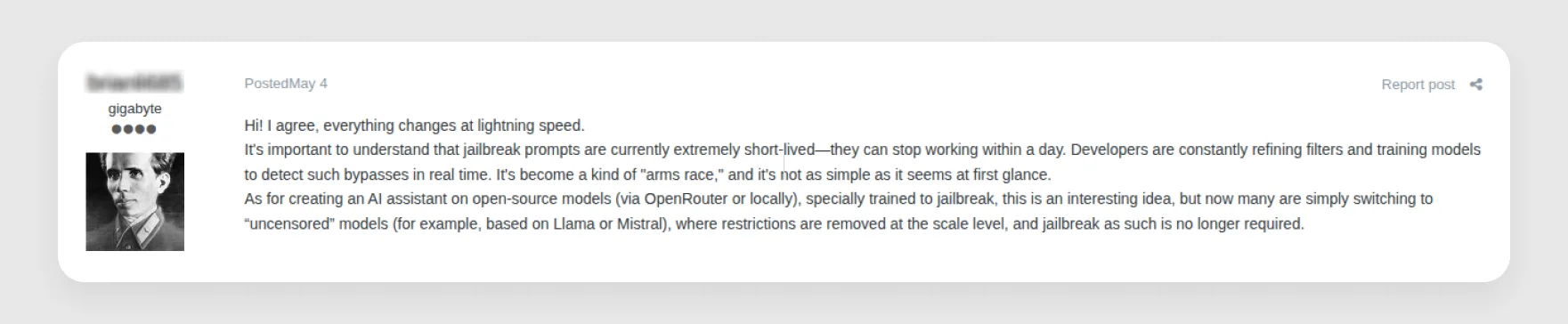
On some forums, entire threads are dedicated to curating and ranking uncensored models, with titles like "ULTIMATE AI UNCENSORED LIST V2 + TOOLS."
That's the path-of-least-resistance dynamic showing up in AI use. Threat actors aren't all chasing the smartest model available. They just want the least restrictive, most reliable model that's still good enough for the task and cheap enough to operationalize at scale.
Forum users are explicit about the trade-off. In a post responding to complaints about guardrails and the need to frame requests as if they came from a "certified information security specialist" working in a lab, one user put it bluntly: "You're probably talking about GPT models. Their censorship gets stronger and stronger with each update. It's been unusable for a long time now." [translated from Russian]
The conversation, in other words, is moving from "How do I get around safety guardrails?" to "Which model gives me the fewest operational constraints?"
For defenders, that's a useful reminder that guardrails still matter. They don't have to be perfect to be worthwhile. If they push actors off higher-capability frontier models and onto weaker, less polished, or less reliable alternatives, they still reduce the quality of adversarial AI use.
AI Access Brokers Are Emerging
We also observed growing interest in higher-trust or special-access tiers tied to major AI providers, especially programs intended for verified defenders doing legitimate cybersecurity work. These tiers are designed to give vetted security teams more usable access for approved cyber workflows, and they're already attractive to legitimate users who value their higher reliability and operating flexibility. In underground discussions, they're increasingly viewed as more reliable and less restrictive options for cyber-related tasks. The result is something close to an access-broker market for AI: actors offering accounts, API access, or trusted-tier credentials to users looking for fewer guardrails, lower ban risk, and more reliable model behavior.
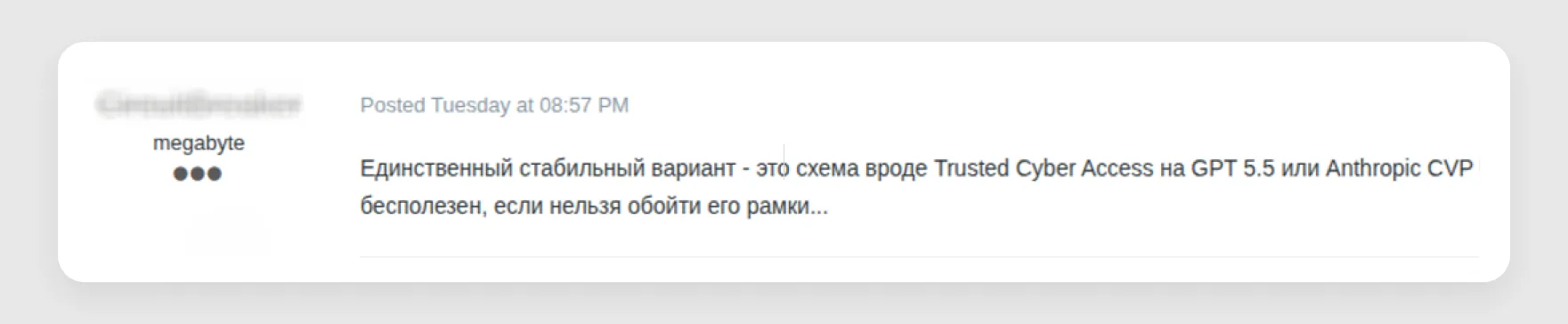
After an actor claimed that "the only stable option is a scheme like Trusted Cyber Access on GPT 5.5 or Anthropic CVP with Opus 4.8, even if Fable 5 is smarter. Even the smartest model is useless for our purposes if you can't bypass its restrictions..." in a forum thread (see Figure 13), multiple users asked how such accounts could be obtained. One claimed to have already paid someone $500 to get one.
In response to this demand, a user advertised these accounts priced initially at $140 and gradually increasing up to $600 due to "high demand" (see Figure 14), posting their offerings on multiple threads. The same actor also claimed to resell official API keys "for 80% off the official price" for use across multiple AI models, explicitly welcoming customers using "self-replicating AI agents" for malicious activity.
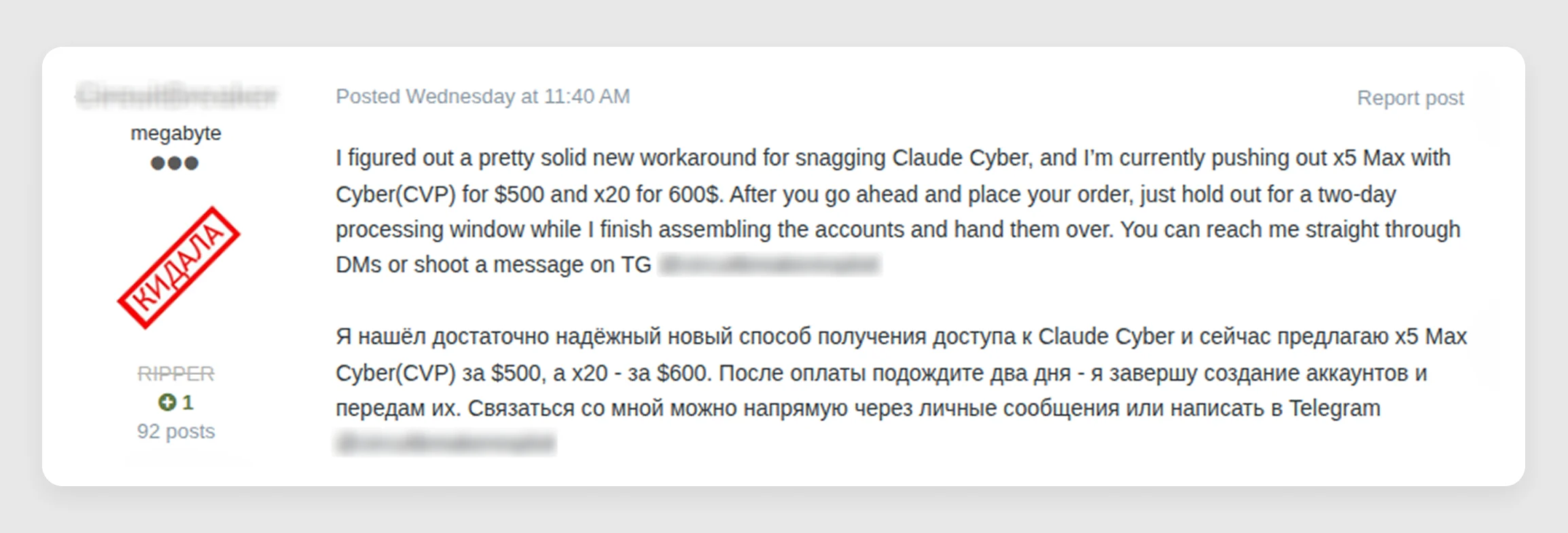
While the credibility of these claims can't be fully verified, it's clear there's demand, and the appearance of such an eager "AI access broker" shows how quickly underground threat actors adapt to the market.
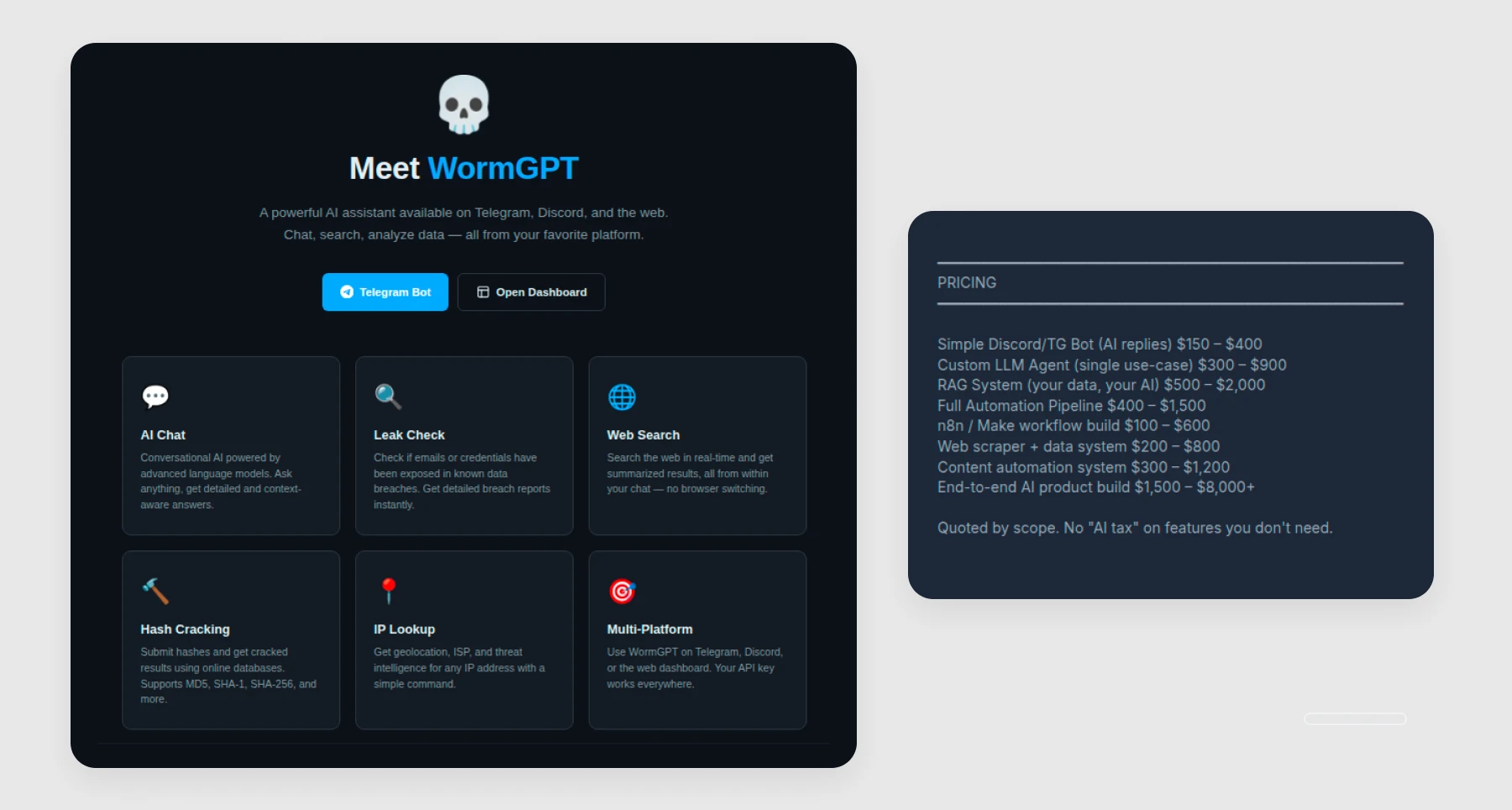
Aside from model choice, cost and reliability also shape how AI fits into real operations. DPRK workers and, reportedly, ShinyHunters are using legitimate and open-source AI platforms rather than custom-built malicious software. The same logic shows up in pricing. Malicious AI assistant "WormGPT" (a copycat version of the now-defunct original) subscriptions were advertised for as little as $15 or $50 per month, depending on subscription level (see Figure 15).
At the other end of the market, face-swap software for images and videos advertised as able to bypass AI detection controls was offered for $800, while end-to-end AI product builds by an actor claiming 2 years of AI work ranged from $1,500 to over $8,000 (see Figure 16).
For threat actors trying to multiply operations at scale, those higher prices will almost certainly push most toward cheaper alternatives, i.e. repurposed mainstream models, open-weight models, and light customization layered into existing workflows.
For defenders, that means the issue isn't limited to obviously malicious GPT clones on the dark web anymore. The more likely reality, and the one reflected in the incidents throughout this report, is threat actors plugging off-the-shelf AI into established fraud and intrusion workflows wherever it saves time or effort.
Criminal AI Use Is Becoming More Specialized
A second theme in the data is specialization. These posts weren't just broad questions about prompts or malware. Some were explicit hiring or build requests, including software for an AI call center, face-swap capability, and LLM expertise in model production, APIs, and restructuring. In several cases, multiple people offered help. That points to a labor market forming around criminal AI enablement, not just casual experimentation.
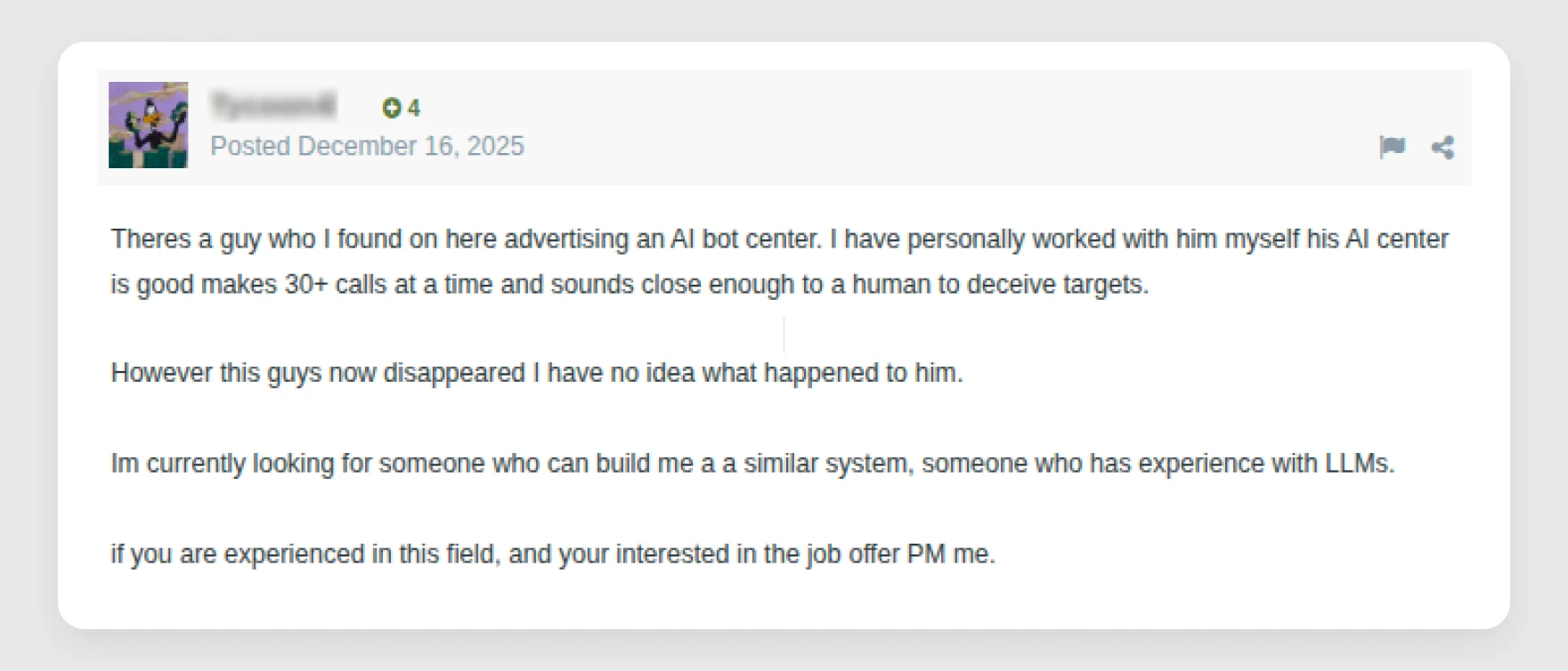
Those services map closely to the incidents in this report. Demand for AI call-center tooling aligns with the growth of vishing and ShinyHunters-style social engineering, where scale and real-time script adaptation matter. Face-swap and identity tooling map directly to DPRK remote IT-worker fraud, where the challenge is sustaining a believable persona across resumes, photos, interviews, and meetings. Requests for help with APIs, model production, and workflow components suggest some actors are moving beyond prompt use and into integration work: connecting models to bots, fraud tooling, and repeatable operational pipelines.
The most operationally mature discussions we reviewed were around deepfakes, KYC bypass, and identity fraud. In one detailed forum post, an actor laid out two separate approaches to defeating identity verification at scale: one technically demanding and focused on interception and manipulation, the other centered on live impersonation through deepfake presentation.
These conversations show threat actors treating AI as operational infrastructure; i.e., something to hire for, standardize, and plug into existing fraud and intrusion workflows.