

How to Trust AI Before You Let It Drive
No high-stakes industry operates without universal standards. Hospitals can’t operate without ongoing clinical peer review. Planes can't take off without continuous assessment. These fields established standards for testing and validation because the cost of failure demanded it.
Artificial intelligence has entered this upper echelon of critical industries, yet there are no established universal standards for AI to meet before or after it’s deployed. Meanwhile, a lack of AI testing and validation standards continue to increase risk and reduce trust for organizations.
Before AI can be trusted to operate at scale, there needs to be an agreed-upon framework for continuous AI testing and validation.
ReliaQuest has created the universal standard for AI testing and validation, which serves as the foundation for building trust in AI across every field.
Understanding The Mistrust of AI
The value of AI is clear, but it has been met with skepticism and mistrust. Security operations teams have seen firsthand where AI can fall short:
Plausible outputs that are factually wrong
Automated actions applied to the wrong host or context
Escalation of false positives that waste time and erode confidence
Performance drift over time that goes undetected
These risks have played out across countless SOCs, resulting in hesitation from leadership to deploy AI. Organizations that should be accelerating remain anchored to manual processes because vendors haven’t adopted a universal standard of continuous AI testing and validation.
And the testing that most vendors are doing hasn't fixed this problem. The typical approach is a pre-launch evaluation, where teams confirm the system works in a controlled testing environment, then deploy it and move on. Many security teams also add spot checks or informal feedback mechanisms after launch. None of these approaches have built the trust needed for AI to operate at scale.
AI testing and validation cannot be a periodic process. For AI to be trusted, it must adhere to a cyclical standard of testing and validation that runs continuously before, during, and after deployment.
ReliaQuest’s Standards of AI Testing and Validation
The following framework comes from operating the security teams of the world’s largest and most complex organizations, learning exactly where AI succeeds and fails in production.
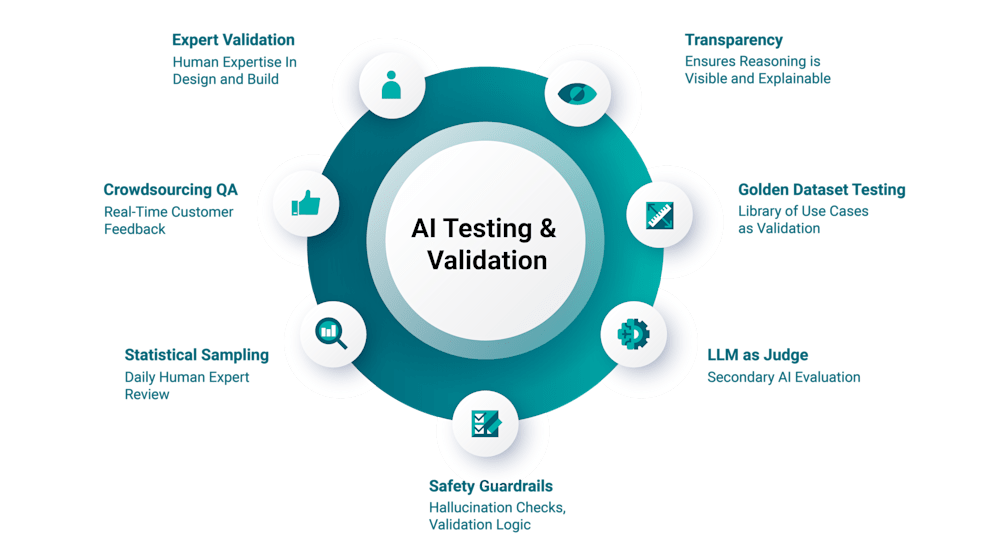
ReliaQuest applies each standard as a continuous cycle of AI testing and validation. These standards run continuously, and the cycle repeats as environment, data, and risk evolve.
Standard | What It Enables | Risk It Addresses | How ReliaQuest Applies It |
|---|---|---|---|
Expert Validation | Design shaped by subject matter experts who understand real investigative workflows. | Outputs that sound correct but conflict with operational reality. | ReliaQuest experts are embedded in the development process and validate every prompt and response through transparent mode testing before prompts go live. This human-in-the-loop approach ensures that critical security decisions benefit from expert judgment with context from ongoing user interviews. |
Safety Guardrails | Layered controls that constrain misuse while protecting sensitive context. | Prompt injection, unsafe responses, unintended scope expansion. | A prompt guarding system detects and filters malicious inputs, including prompt injections and jailbreak attempts, while RAG ensures output accuracy. System rules ensure consistent outputs and enforce security boundaries to form multi-layered protection. |
LLM as Judge | Objective quality control using a specialized language model to evaluate the primary model's output. | Optimization bias and overlooked quality gaps. | A separate language model is used as an automated reviewer in a double-blind comparison to score or rank an AI system’s outputs against a consistent rubric. This enables prompt migration as models evolve, so validation is never locked to a single model. |
Golden Datasets | Consistency baselines built from real investigation scenarios. | Silent regression and performance drift. | A curated library of validated use cases is tested after every system change to detect shifts in reasoning, timing, or evidence prioritization. Scored evaluations run across golden datasets and real-world cases to detect regression and drift. |
Statistical Sampling | Expert focus on nuance and emerging patterns. | Drift that automated checks fail to detect. | ReliaQuest experts systemically review statistically significant samples of AI-handled alerts, comparing human-driven conclusions against system verdicts. This surfaces emerging patterns and subtle reasoning shifts to catch what blind automation misses. Results are then surfaced through transparent reporting and audit trails so stakeholders can review what changed and why. |
Transparency | Visible validation results, decision rationale, and testing methodology shared with stakeholders with stakeholders for straight-forward audits. | Blind trust, unverifiable claims, and accountability gaps. | Customers can see exactly how the AI reached its conclusion at every step of the investigation process. Decision rationale and testing methodology are always visible within GreyMatter. |
Crowdsourced QA | Customer feedback loops grounded in real production behavior. | Edge cases that labs never simulate. | Customers provide thumbs-up or thumbs-down feedback directly in GreyMatter, with a free-text option for detailed feedback. Every thumbs-down is reviewed by ReliaQuest experts and fed back into the testing and validation cycle to ensure our AI learns from real-world usage. |
What matters most is how these standards reinforce one another. Remove one, and a category of risk goes uncovered. Implement them all, and you build a systemic and cyclical accountability framework that makes AI trustworthy to drive daily operations.
ReliaQuest’s agentic AI security operations platform, GreyMatter, operationalizes these AI testing and validation standards to ensure every decision it makes is accurate and transparent. With these standards in place, over 1,000 of the world’s most trusted security teams depend on GreyMatter to drive their security operations at scale—moving out of reactive processes and into proactive and even predictive security operations.
